











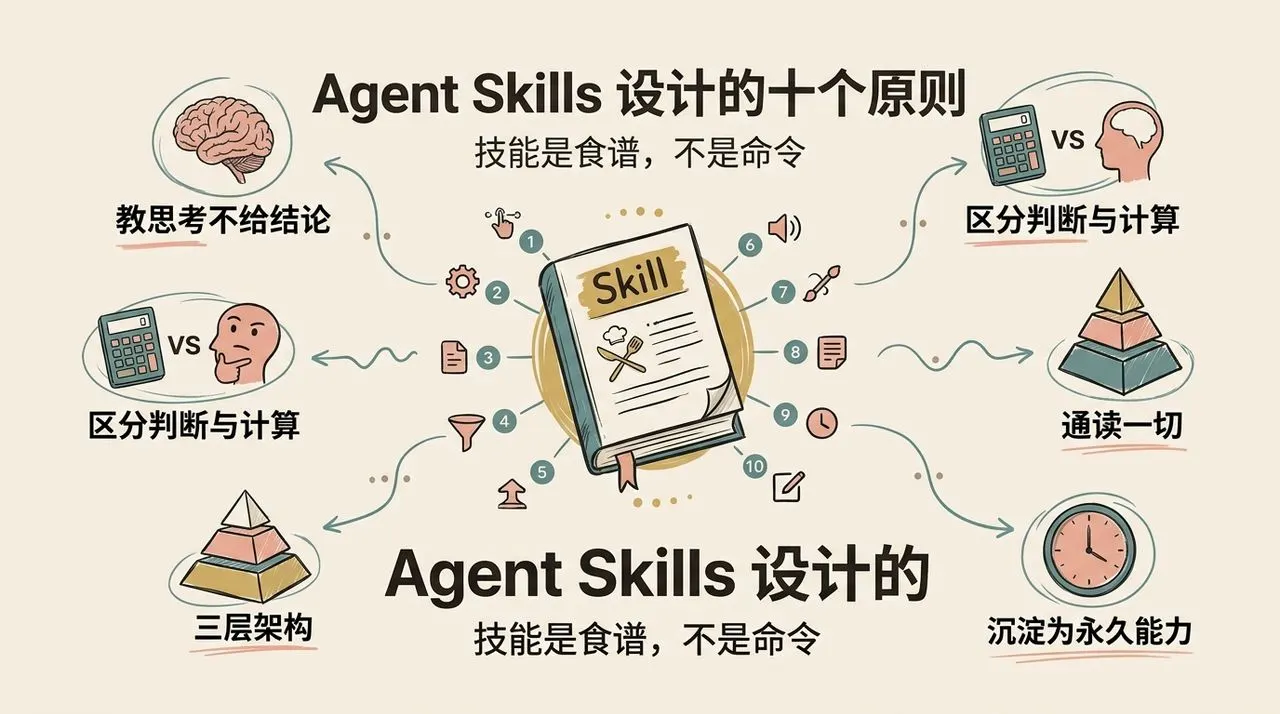
Agent Skills 设计的十个原则:为什么你的 AI 助手总在重复劳动
为什么有人用 AI 拿到 100 倍结果?
同样一个模型,有人做一次性问答,有人搭建持续进化的系统。差距不在模型,而在 Skills。
Carlos E. Perez(@IntuitMachine)最近发布了长文《Ten Design Principles of Agentic AI Skills Design》。读完之后,我觉得这套方法论值得每个 AI Agent 爱好者认真拆解。
Perez 的观点很直接:获得 100 倍结果的人并不更聪明,他们只是无情地将工作沉淀为 Skills。
下面逐条梳理这十个原则。
原则一:Skill 是食谱,不是命令
大多数人写 Skill 时,容易犯这样的错误:
“分析客户反馈并总结主要趋势。”
这不是 Skill,这是命令。所有具体信息都硬编码在内,只能用一次。
真正的 Skill 应该像食谱,有参数,有流程:
| 要素 | 说明 |
|---|---|
| 参数 | 语料库、研究问题、深度级别 |
| 流程 | 通读 → 识别模式 → 命名主题 → 提取案例 → 撰写报告 |
命令是一次性的,食谱是可复用的。一个设计良好的 Skill 可以处理数百种场景 —— 客户反馈、员工调研、学术论文,只需更换输入参数。这要求我们从「具体问题解决者」转变为「方法论设计者」。
原则二:教思考,不给结论
如果你在 Skill 里预设了结论:
“第四步:得出证据支持患者安全担忧的结论。”
AI 就成了确认偏误的工具。你预决定了结果,把 AI 变成了傀儡。
正确做法是教它如何权衡:
- 支持和反对假设的证据分别是什么?
- 时间线是否合理?
- 是否存在替代解释?
- 什么证据会改变你的看法?
检验标准很直接:同一个 Skill,能否用来论证相反的结论? 如果能用「调查举报者」Skill 既证明「此人被压制」又证明「举报毫无根据」,并根据证据得出不同答案,这才是真正的 Skill。
原则三:明确划分判断与计算的边界
Perez 用了一个很直观的例子:
| 场景 | 类型 | 谁更适合 |
|---|---|---|
| 安排 8 人晚宴座位 | 判断 | AI ✅ |
| 安排 800 人座位 | 计算 / 优化 | 传统算法 ✅ |
8 人座位是判断问题 ——AI 能感知社交动态,做出合理权衡。800 人座位是优化问题 —— 需要算法,不是直觉。AI 没有这个算法,所以它会幻觉出一个看似合理却违反约束的方案。
别让 AI 做算术,也别让计算器做解释。
Skill 应显式标注:
- 哪些步骤需要判断 → 让 AI 思考
- 哪些步骤需要计算 → 调用工具
这个边界经常被模糊,但它是系统可靠性的基础。
原则四:魔力在于「通读一切」
数据库查询做不到的是:阅读一个人的 50 份文档,发现矛盾,追踪叙事变化,写出一页档案。Perez 把这叫做 「日志化」(Diarization)。
真实案例:
会议组织者的数据库显示申请者做「AI 基础设施」。但 1 对 1 谈话暴露他们主要担心计费和成本归因。GitHub 提交显示 80% 近期工作在支付模块。
别预过滤「相关」文档。直到读完才知道什么相关。力量来自看到全貌后涌现的综合 —— 这是 AI 相比传统查询的独特优势。
原则五:在正确时刻加载正确文档
Perez 分享了自己的失败教训。他写过 20,000 行指令,涵盖每个怪癖和模式。结果更糟 ——AI 的注意力有限,信息过载让重要指令被淹没。
解决方案是 200 行指针:
当你做 X 时 → 加载文档 Y当你看到模式 A 时 → 查阅 Skill B这叫做解析器(Resolver)—— 一个路由系统,在正确时刻加载正确上下文。
想想写代码时的 import。你不会把所有库的文档塞进一个文件,你只在需要的时候导入。Skill 系统也一样: 按需加载,而不是全量注入。
原则六:智能向上推,执行向下推
三层架构模型:
- 顶层:Skill — 丰富的流程、判断、智慧文档
- 中层:Harness — 约 200 行代码,运行 AI 循环、管理上下文、调用工具
- 底层:Tool — 快速、简单的程序,做一件事且可靠
反模式是「胖框架」——40 个工具定义占满上下文,业务逻辑嵌在编排层,Skill 反而成了附属品。
原则:智能推入 Skill,执行推入工具,保持框架纤薄。 当模型改进时,所有 Skill 自动改进;工具保持可靠,因为它们只是代码。
原则七:快而窄胜过慢而通用
通用工具是陷阱。Perez 列出了三个问题:
| 问题 | 具体表现 |
|---|---|
| 慢 | 通用浏览器工具 15 秒 vs 专用工具 100ms,相差 150 倍 |
| 臃肿 | 40 个工具定义耗尽 AI 注意力预算 |
| 隐藏复杂性 | 工具试图「智能」时,判断被埋在看不见的地方 |
构建快速、狭窄、甚至「愚蠢」的工具。 每个做一件事,半秒内完成,不解释不决策。
软件不再珍贵。需要什么工具就建什么,30 分钟搞定,AI 还能帮忙写。不需要就删。工具是脚手架,不是建筑。
原则八:追逐「还不错」
用户对 AI 输出的三种反应:
优秀 ← 还行 → 糟糕大多数人专注于修复「糟糕」的响应。它们很戏剧化,感觉很紧急。但反直觉的洞察是:「还行」才是改进的空间所在。
- 「糟糕」通常是明显失败 —— 系统崩溃、工具超时。这些是 bug。
- 「还行」意味着系统几乎工作了,但某些东西差了一点。这些是机会。
真实案例: 活动匹配 Skill 有 12% 的「还行」评级。添加一条规则后降到 4%:
当某人说 AI 基础设施但代码主要是计费,将其归类为 FinTech。
这条规则来自审视「还行」与「优秀」之间的差距 —— 精准修补,而非重写整个流程。
原则九:写一次,永远运行
“如果你必须要求两次,你就失败了。”
每个 Skill 都是系统的永久升级:
- 被保存、版本化、永久可用
- 凌晨 3 点运行,处理千次实例不疲倦
- 当模型改进时,每个 Skill 自动升级
更好的模型 + 相同的 Skill = 更好的产出
如果系统有 100 个 Skills,每个处理一类工作,每个随模型改进自动升级 —— 这不是一套工具,而是一个持续复利的资产。停止把 AI 交互当对话,开始把它当构建永久能力的机会。
原则十:相同流程,不同世界
一个 /match 的 Skill,接受三个参数:
| 参数 | 作用 |
|---|---|
| ENTITIES | 匹配谁? |
| CRITERIA | 什么是好匹配? |
| CONSTRAINTS | 必须遵循的规则? |
同一套流程,三种完全不同的场景:
| 场景 | ENTITIES | CRITERIA | 输出 |
|---|---|---|---|
| 会议分组 | 1200 名创始人 | 行业相似性 | 同行分组 |
| 缘分午餐 | 600 名创始人 | 跨行业新颖性 | 惊喜组合 |
| 即时社交 | 大楼里的人 | 最近邻嵌入 | 1:1 配对 |
相同 Skill,相同七个步骤,完全不同的行为。 参数提供具体世界,Skill 提供流程。设计一次,永久调用。
写在最后
这十条原则指向同一个方向:沉淀(Codification)。
遇到重复任务,沉淀为 Skill。注意到有效的判断,沉淀如何做出它。发现模式,沉淀模式让系统识别它。
一年后,你的 Skills 将运行在比今天更好的模型上。你现在写的每个 Skill,都是对未来能力的投资。你沉淀的每个判断,都将成为永远不会失去的杠杆。
写好食谱,做好不同餐食。系统复利增长。构建一次,永远运行。
支持与分享
如果这篇文章对你有帮助,欢迎分享给更多人或赞助支持!